Word Art with Python and SVG's
29 Dec 2017
This started with a text from my aunt. She wanted me to replicate an effect found here.

The premise of this art is that each sentence is broken down and saved as the sum of the contained words - e.g. the sentence “This is a wonderful day!” will be saved as 5 for our program. The Path will move in a given direction for that length, and then turn 90 degrees to the left. Any time you see a long unbroken sentence, you can be sure the author has been letting their thoughts (and pens) wander.
Here’s the end result for two of her books.
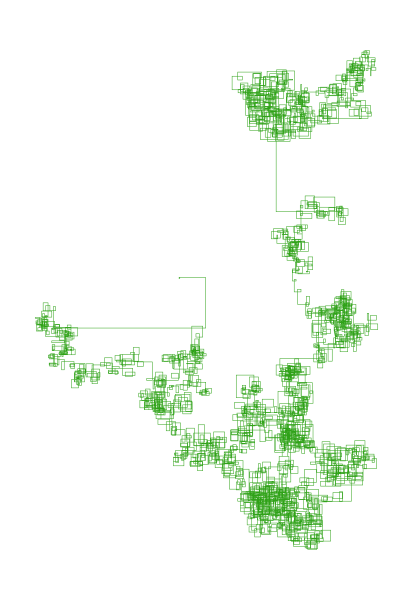

There were a few distinct problems to solve. I have detailed them below. All of the code and example images are here: https://github.com/daviseford/word-art
Parsing Text
Well, what’s a sentence? Luckily, I didn’t need to concern myself too deeply with that idea. I used the Natural Language ToolKit library for Python and went about tokenizing input text. This was easier than I imagined:
import nltk # http://www.nltk.org/
from nltk.tokenize import TweetTokenizer
import string
import io
def read_file(path):
try:
f = io.open(path, mode="r", encoding="utf-8") # Using io allows us to specify the encoding
return f.read()
except Exception as e:
raise e
def get_sentences(input_text):
try:
tokenizer_words = TweetTokenizer()
tokens_sentences = [tokenizer_words.tokenize(x) for x in nltk.sent_tokenize(input_text)]
sentence_words = [filter_alpha(x) for x in tokens_sentences]
return sentence_words
except Exception as e:
raise e
def filter_alpha(a_list):
stripped = [strip_non_alpha(x) for x in a_list]
return [x.lower() for x in stripped if x.isalpha() and x is not None]
def filter_length(list_of_sentence_lists):
return [len(x) for x in list_of_sentence_lists]
def strip_non_alpha(word):
exclusion_list = set(string.punctuation)
return ''.join(x for x in word if x not in exclusion_list)
def get_sentence_lengths(path_to_src_text):
input_text = read_file(path_to_src_text)
sentences = get_sentences(input_text)
return filter_length(sentences)
# print get_sentence_lengths('./txt/bible.txt')
# [44, 33, 55, 11, 110, 23, 88, ...]Now we’ve got a list of sentence lengths. We combine that with a little geometry, the wonderful svgpathtools, and some good old fashioned computing.
The end result is a script that takes in a filepath (a plaintext file), and optionally a color parameter for the generated line.
The script’s argument structure means I get to run commands like:
python svg.py -f ./txt/romance_of_lust.txt --color "red"
python svg.py -f ./txt/wizard_of_oz.txt --color "yellow"
word-art $ python svg.py -f txt/purple_cow.txt -c purple
txt/purple_cow.txt has 282 sentences
Done! Created /word-art/output/purple_cow.svgWell, that’s a lot of code you don’t care about. How about some pictures?
All of the below images are generated from the text provided by Project Gutenberg. I used a selection of their Top 100 books.
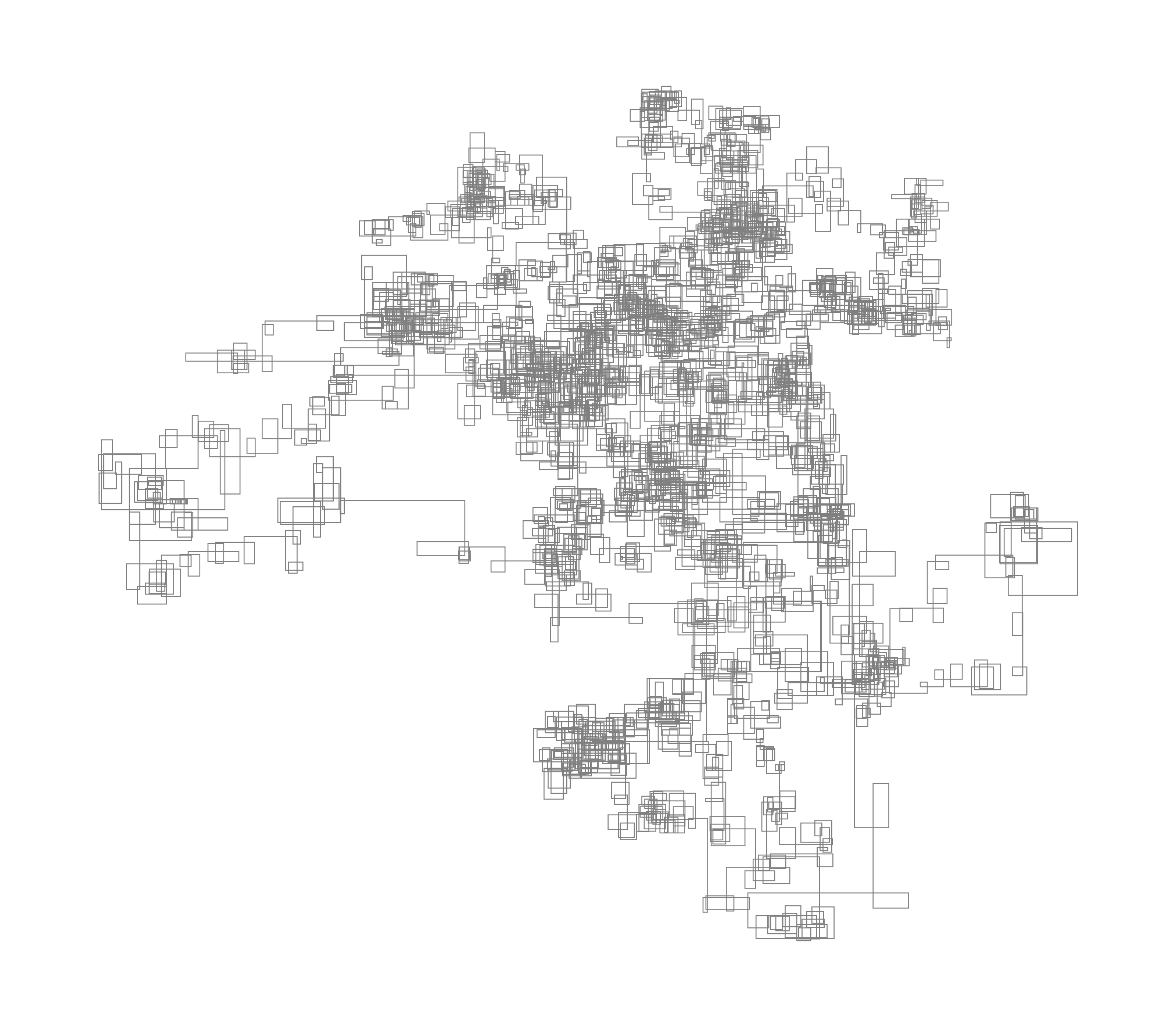



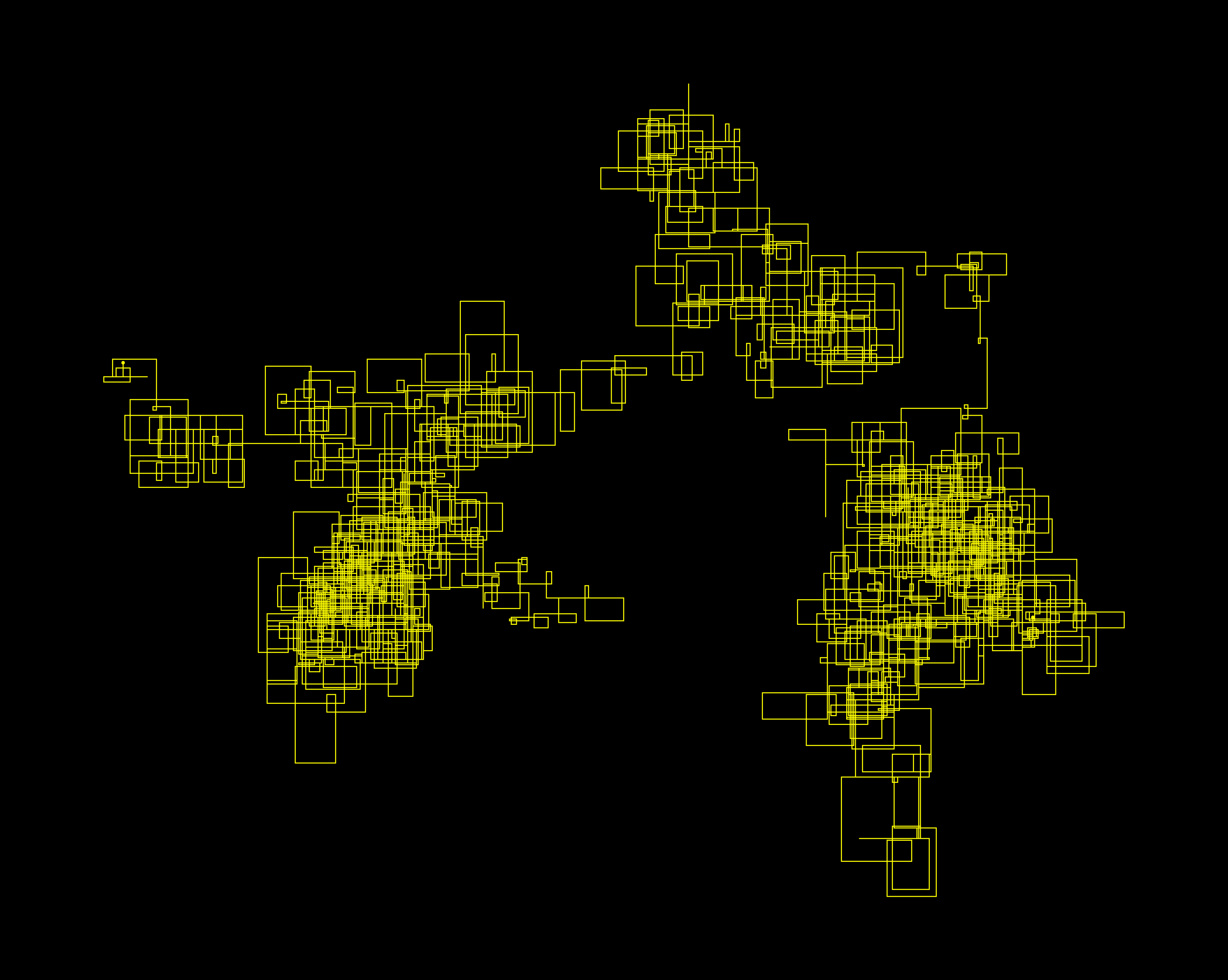
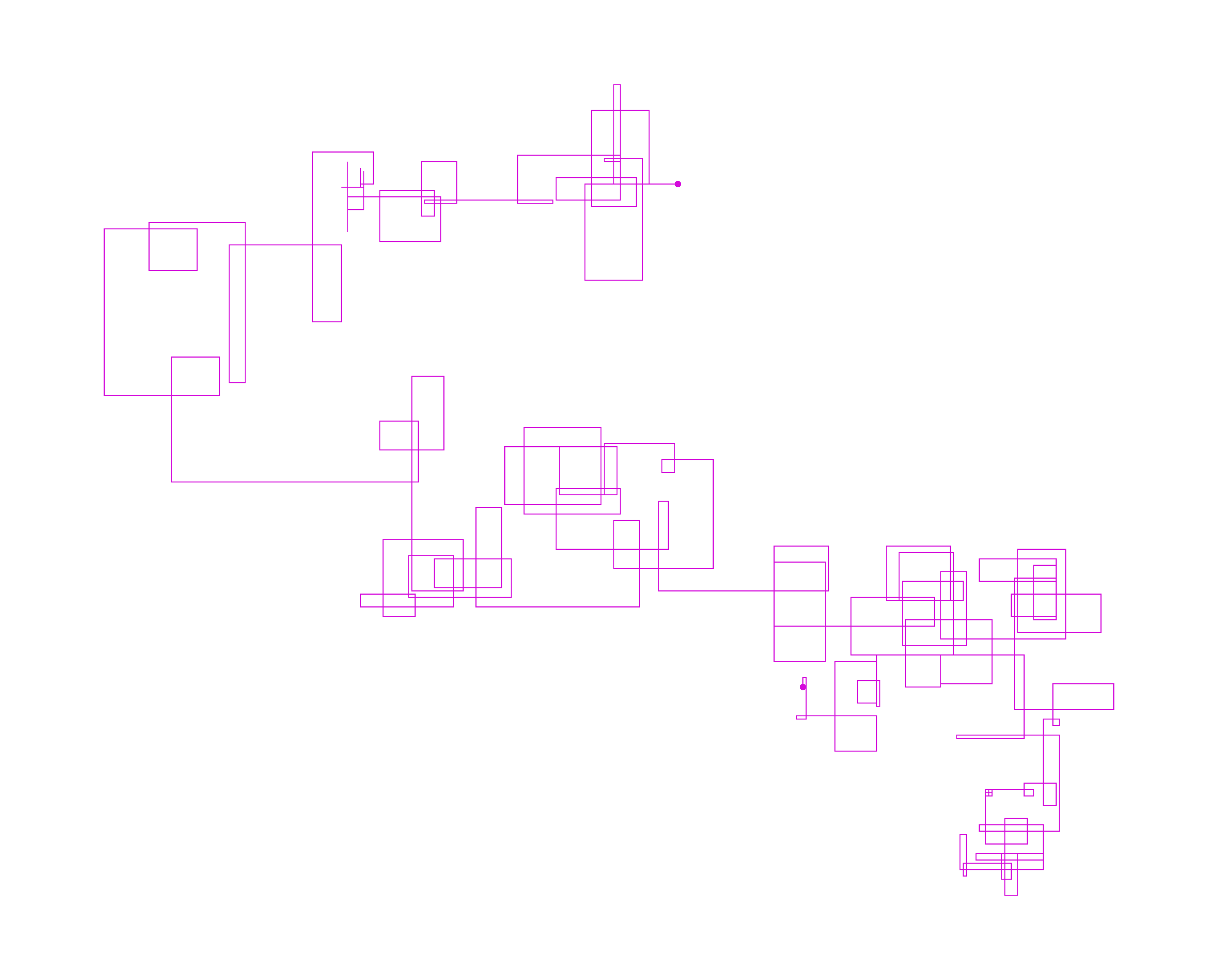

I hope this isn’t too much for you - here’s this article.

Related Posts
Helpful Bash Script - git reset all
22 Sep 2021Get a Pull Request by Number - Bash Function
22 Sep 2021Creating Effective Presentations with stock Apple applications
21 Sep 2021Air Cooling a Buttkicker Gamer 2
27 Feb 2021