AoS Reminders - One Year Later
13 Sep 2020
It’s been one year since I launched AoS Reminders “for real”. Before this date last year, it was a side project that started as something personal for me and evolved into a community-driven website.
We’ve gone from a small website with zero UI and exactly one army (Seraphon) to a huge open-source community-driven project with contributions and help from tons of community members with well over 500 active subscribers.
We have an incredibly high subscriber retention rate - only around 60 people have ever unsubscribed. Our average subscribers stay subscribed for a long time (a year now, in some cases!) and get a ton of use out of the application.
We’ve noticed that some power users really love to save and load different army combinations on the fly. Dark mode has something like a 80% adoption rate among subscribers. And our meta statistics (reviewed by AoS Coach) have helped shape understanding of where the game is heading.
We’ve patched well over 1,500 different issues and bugs along the way. We are communicative and prompt to fix anything that’s gone awry.
Our website has had incredible uptime over the past year. I can’t really take credit for that, it’s just hosted on S3 and S3 didn’t go down this year :)
I’ve met a lot of great people on the journey of launching this codebase and had amazing experiences along the way.
I’ve had the opportunity to work with over 25 contributors to the codebase. It’s helped me personally and professionally, and I’ve loved every minute of it.
I’d like to thank all of my subscribers and the people who’ve helped promote the website.
No man stands alone, and I am profusely grateful to all of the people who have reached out to talk to me, to file bugs, to fix errors, or hell, just to complain. Every bit of feedback and input makes the application better.
When I went to NOVA and saw tables covered littered in AoS Reminders printouts, it helped me realize that I needed to be more conscious of how much whitespace a typical printout used. We rolled out “Compact” mode shortly thereafter, which generally resulted in about 3x less paper being consumed by printouts.
Little changes like that became frequent as we saw the printouts at more and more tournaments. We tried to get better at grouping spells together. We learned that we needed to implement drag and drop to re-order reminders per player preference. We added dark mode (my favorite feature to date).
Some contributors began to really come into their own, adding entire features like Play mode and constant streams of data input and bugfixes.
We learned a lot of things together. And then 2020 happened, and it slowed things down a bit.
A lot less people were playing Warhammer. We still had activity from a few people who were in less-affected countries and those who were using Tabletop Simulator.
Tabletop Simulator on my primary monitor, AoS Reminders on my secondary monitor. This is Warhammer at its virtual finest!
— Davis Ford (@daviseford) April 18, 2020
Personally, I played a few games of Tabletop Warhammer and just didn’t quite feel the excitement I normally felt. I think I need the actual sensation of moving models around and creating physical narratives. The 3D substitute just didn’t do it for me.
It’s been hard to muster up the desire to paint models or start any new Warhammer-related projects.
Every once in a while, I think about writing up a proposal for Games Workshop Warhammer API idea that I’ve been mulling about. I’d really love to see this game move forward in terms of keeping rulesets and players up-to-date.
I had the pleasure of chatting with the guys at Life After The Cover Save. It's like no other podcast I've done before!
— Davis Ford (@daviseford) March 24, 2020
I discuss my vision of an open-source, data-driven AoS ecosystem.https://t.co/JrqbcxaBSb
Shouted out @LLV_Damian , @warscrollbuildr and @AnthonyMagro !
I think that there is a way to bridge the gap between gating information behind a paywall and still offering a solid user experience for both free and premium subscribers.
Coding-wise, I have solved some gnarly bugs this year that I’m pretty proud of. We have a great test suite with over 500 unit tests. We have a fairly bulletproof, offline-first application that users can always depend on. We always have consistently fast page load times (under 2s). We do not display ads. We have a build pipeline that allows newcomers to come in and contribute without fear of breaking anything else in the codebase.
AoS Reminders does one thing and it does it really well. That’s how I think tools should work.
You know, I really love Warscroll Builder. I think that one day I’d love to see a button on that application that says “Export to AoS Reminders”. Just a shower thought.
But I think the AoS community is currently pretty well served in terms of AoS Reminders, Warscroll Builder, and Azyr. I still wish I could get some form of official guidance or communication from Games Workshop. I’d love to work more closely with them.
I have really liked the new rules coming out and the look of new models. I think Games Workshop is taking this game in a positive direction.
I really hope to get back to gaming and playing with friends. I think as the months get colder and I’m forced indoors, I’ll come back to the game with more vigour.
I haven’t totally slouched during the pandemic. I’ve completed 4 Mournfang Riders, 8 Ironguts, 2 Stonehorns Beast Riders, and Giant!
I’m calling these done! Started in January.
— Davis Ford (@daviseford) June 23, 2020
Aleguzzler Gargant
4 ironguts
4 frost sabers
4 mournfang riders pic.twitter.com/pUs2bneW1o
I think I’ve sufficiently rounded out my Ogor collection. The Lumineth Realmlords aren’t really my style.. we’ll see what interests me in the future.
I had big plans this year. I had 5 different tournaments lined up. I gave a ton of merch to Adepticon and was planning on attending as well. I was going to be interviewed by some podcasts. I was going to meet some of my Warhammer heroes. I was practicing tournament lists with local players. I was reading up on the meta and asking experienced, high-profile players for their advice.
And then it just… stopped.
I wrote this post because I wanted people in the AoS community to know that we’re still alive, we’re still kicking, we’re still improving and helping players around the world.
Although the pace of development has certainly slowed down, we’re still committed to providing an amazing gaming aid for Age of Sigmar players. AoS Reminders will always be kept up to date with timely updates.
I’m even planning a new feature that will be announced shortly… stay tuned.
If you like this article, or the work I’ve done on this project, consider subscribing to support me. It would be a pretty cool thing to do!
In the meantime, I’ve been busy working on my house, specifically my front and back lawns. I’ve been hanging out with my girlfriend, Amanda, and I am so thankful I have her during these times.

I have been playing a lot of Rocket League and lately, Fall Guys.
I will be presenting a talk at JupyterCon 2020 in October. It’ll be interesting if you’re into React, Typescript, or JupyterLab. I’ll post it to this blog once it’s public.
I hope you and your family and friends stay safe and have a good, uneventful rest of 2020.
Take care.
Fix for Screen Tearing in Chromium on Raspberry Pi
28 May 2020
If you’re noticing screen tearing, stuttering, and generally unpleasant performance in Chromium on Raspberry Pi, here’s a fix I found for it.
Step 1 - Enable Hardware Acceleration
You’re going to want to launch Chromium with the use-gl flag set to egl.
This lets us use OpenGL ES, which will strongly improve Chromium’s rendering performance on the Pi.
# Launch Chromium with the use-gl flag which enables hardware acceleration
/usr/bin/chromium-browser --use-gl=egl
Once you’ve launched Chromium with the above flag, navigate to about:gpu to check your results.
Step 2 - Disable xcompmgr composition manager
Next, we’re going to disable the xcompmgr composition manager.
# Open configuration prompt
sudo raspi-config
Navigate to Advanced Options -> Compositor -> xcompmgr composition manager -> Choose “No”
Enjoy!
That should resolve most issues! I still noticed a tiny bit of screen tear on certain translate3d CSS animations, but the difference is night and day after applying these tweaks!
Run a startup script after GUI loads - Raspberry Pi 4 w/ Raspian
28 May 2020
If you’re running Raspian on a Raspberry Pi 4 and want to execute commands after the GUI has loaded, here’s how.
First, we’re going to open the autostart file.
# Note: Do NOT run in sudo mode. You will edit the wrong file!
nano ~/.config/lxsession/LXDE-pi/autostart
And we’re going to add the following:
@lxpanel --profile LXDE-pi
@pacmanfm --desktop --profile LXDE-pi
# Run a sample bash script
@sh /home/pi/your/script.sh
# Or a sample python script
@python /home/pi/python_script.py
Hit Ctrl + X to write changes to disk, Y to confirm, and Enter to save the file.
That’s it! Go ahead and run sudo reboot to test it out!
I use this strategy to run a python server and React-powered UI for a digital photo frame.
Enjoy!
Note: Make sure that you’ve run sudo raspi-config and set Boot Options to Desktop Autologin for best results.
Build Log - Digital Picture Frame for my Nana
26 May 2020
This blog post will track my attempt to build my Nana a custom digital frame.

This came about because I’m occasionally on a phone call with Nana and I want to send her a photo to look at - some art I’ve done or something.
Nana does not have a smart phone or email, and she doesn’t care for them anyways.
What I need is a digital frame that I can send pictures to in real time, and runs a slideshow of all images.
I don’t want to log in to some website to upload photos, and I want my family to be able to email or text photos to this digital frame.
I’m going to use a Raspberry Pi, React, AWS, and some elbow grease to get this all running. Let’s get started!
Strategy
While the OS installs, let’s talk about our strategy for the pictures (and videos?)
The overall goal of this project is to provide the following
- A “digital picture frame” for my Nana, which consists of
- A 10” HDMI screen with sufficient resolution to display photographs beautifully
- A Raspberry Pi running the show behind the scenes
- An easy method of sending pictures to the digital frame
- Ideally, an SMS number or an email
- I do not want to require users to log in to any websites or anything like that.
I’ll loosely divide these two goals into the Media Intake and Media Display phases.
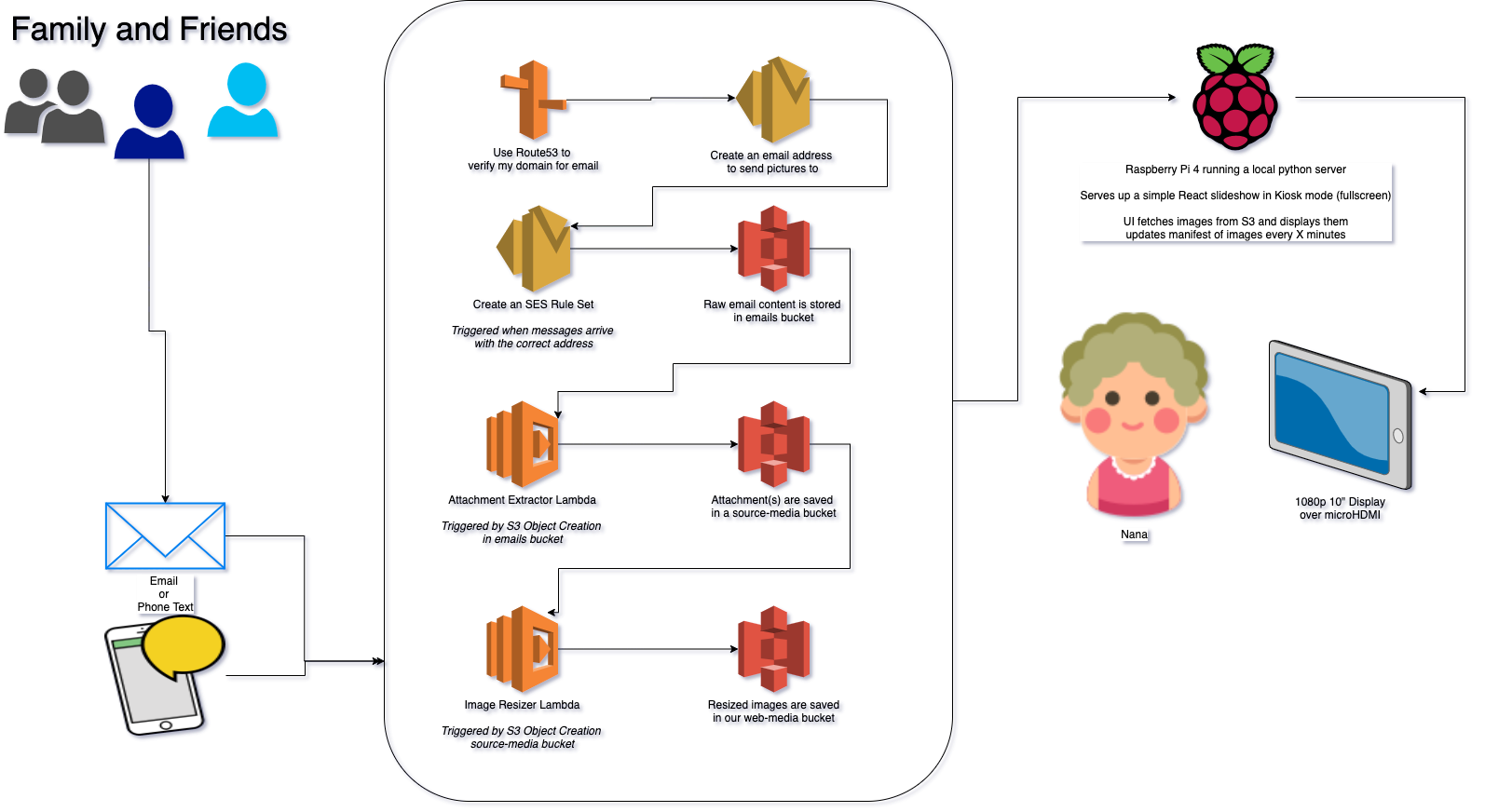
Media Intake
What I want to do, in simple terms, is provide an email or SMS number that a casual user can send a photo, multiple photos, or (stretch goal) a video to.
My first thoughts involve AWS SES for the email recieving component, and then a series of Lambda functions that extract attachments from the email file and save them to an S3 bucket.
Media Display
I am pretty poorly skilled with regards to hardware, so I’m really glad that the CanaKit Raspberry Pi is pretty complete out of the box. It supports HDMI, Ethernet, 4 USB ports, and comes with a pre-formatted SD card loaded with multiple OS options.

On the Pi, I think I’ll only need to write a couple scripts.
- One will control a gallery in a web browser
- It will reach out to an S3 bucket and ask for the latest 50 filenames, and then display them.
- No files are stored locally.
- I probably need to write a startup script that opens the browser to the correct page.
- I want my nana to have basically zero interaction with this frame.
- To her, it should just be a digital picture frame.
Looks like NetSurf is installed by default on my Raspian installation, I’ve never used it, but let’s go for it. We can always grab Chromium later if needed.
First stabs
I’m going to upload a few photos to an S3 bucket and set up a quick photo gallery script that points at the bucket.
I’m using this guide as a basis for getting things running, I always forget what order certain permissions/Cognito operations are needed so I’m glad AWS has good docs.
Well, lol, I just decided that I really needed to use Create React App for this. Totally a good use of time.
Alright, a couple hours later and I’ve got a working picture gallery! It’s correctly fetching images from my S3 bucket and displaying them. It needs more visual polish but it’s functional.
Now I need to move on to…
How Are We Going To Get New Photos?
I’m using this guide now to help set up email forwarding. I think I’ll create an email address using a domain I own and then forward it to S3.
Okay, I set up a bunch of IAM Roles and Policies.
I also verified my domain through SES and created a new Rule Set that saves emails to a bucket.
Okay, hours later, I sorta stalled out and reverted to trying to find a serverless example. I did indeed find one that fit my purposes. I’m now modifying it to save each attachment to an S3 bucket.
Oooo… should I also save any associated text in the body to S3 with a matching filename, so that we can caption the picture later on? Probably!
Updates
Well, I started this on Friday, hoping to pull off a one-day project. Unfortunately, I threw my back out Friday afternoon and had to stop all progress. Now, on Monday, I’m tackling this again. What happened in the meantime?
- I messed up my first PI by doing… something (I don’t know what I did). But now it won’t boot. I’m working on figuring that out.
- My backup ancient Pi also doesn’t work?
- I think the problem may be my SD card, but I didn’t have a micro-SD card reader with which to reflash.
- I went through a lot of issues with Lambda and my own general incompetence when working with AWS.
- I improved the front end UI.
- I successfully set up the email pipeline and had family text photos to the email address I had set up, and it worked!
I ordered a 10” monitor and a new Raspberry Pi 4 (4GB RAM) and started over.
For some reason, my keyboard won’t work with the Pi 4. It’s got LED’s and stuff so I’m assuming it’s too big of a power draw? I don’t know.
I get through installation with just my mouse, and then.. I want to SSH into my Pi to set it up. How do I get the IP of the Pi without a keyboard? Well, let’s just open the router and look at connected devices.
Hacker voice: I’m in
Data Flow
I’ve made a simple flow chart showing the final flow of data.
Tuesday Morning update
Captions are a no-go
I briefly (for about 5 hours) experimented with adding captions and image metadata. I decided against it - due to added complexity and also… I don’t know, people can use Instagram captions if they really care, there are too many issues to cover.
For example…
- If an email recieves a text from a text chain, the “From” field is
[phone number]@vwzpics.com(or something like that)- So I would need a personalized address book of numbers to make that relevant to my Nana, who certainly does not have everyone’s cell phone number committed to memory.
- When an email arrives with a signature, that is displayed and is really annoying.
- Integrating all of the information into the UI without cluttering the screen is tough.
- I would need to educate users that: If you send an email, the body of your email will become the caption on the digital frame - oh but if you send a text, you can’t include a caption.
- Nightmare. No.
Videos are also a no-go (for now)
A generic video sent by text is in the .3gp format. A quick glance shows me that 3gp formats are not fully supported everywhere. So we’re going to ignore videos and move on.
UI Details
- Create React App w/ Typescript (duh!)
- No state management (no Redux or even Context)
- Using the
react-awesome-sliderlibrary.- A very nice library that could really use a refactor into hooks. It’s tough to extend. But it works!
I keep messing up my Pi’s
I managed to brick my new Raspberry Pi already (LOL). Well, it’s not fully bricked, but I need to run it in recovery mode… which requires a keyboard that I don’t have. I ordered one from Best Buy and will pick it up later today.
I am bricking Pi’s at a terrific rate, I’m really learning what not to do! If you have a functioning Raspberry Pi and you want it to not run anymore, send it to my house, I’ll take care of it.
Next steps
Once I get my Pi running again, I think I need to focus on making this reliable.
When the Pi reboots, it needs to automatically start the UI in kiosk mode again without user intervention.
I also need to make sure a casual user can plug this in, set the WiFi settings, and they’re done. My mom will be installing this since she’s the only one allowed in the retirement home (and even then only every two weeks). If any part of this goes down, my Nana will be stuck with a broken monitor that doesn’t display anything - for up to two weeks.
Tuesday Night
Okay, it’s reliable and working!
crontab and autostart scripts are written automatically.
kiosk.sh is called after booting into the desktop and starting a python server locally.
git pull is called every hour in case I push updates out.
I fixed the screen tearing issue which had been causing me major problems!
Transitions between photos are now smooth as butter. Love it!

It’s pretty much ready for drop-off and testing. I just need to run it for a couple hours to test it.
First test - success!
I took the whole kit over to my parent’s house and set it up there. My mom is going to be responsible for setting this up in my Nana’s condo, so it was important to get her familiar with how the hardware and software worked. Luckily, all that’s really needed is for the Pi to be logged into the WiFi network once. After that, it should be bulletproof.


Will report back when it’s installed!
Installation - success!
My mom took the Pi + display over to my Nana’s retirement home and set it up.
This was no small task - unfortunately, they use a captive login method of logging in to WiFi (like logging into a hotel, you have to open a browser and enter a username/password).
In order to get on the facility’s network proper, my poor mom had to grab the MAC address of the Pi and give it to IT support. We then had to wait 20 minutes for the changes to propagate.
In the end, it was definitely worth it - hearing my Nana ooh and ahhh over the phone made this whole project worth it.
We’ve sent out an email to the family on how to send pictures to the Pi.
Next up - I’m going to write a more coherent how-to article for anyone looking to do a similar project. I’m also going to clean up and condense all of my code. Stay tuned!