AWS RTMP Live-Streaming/VOD Solution using MediaLive, MediaPackage, CloudFront, and S3
24 Dec 2018
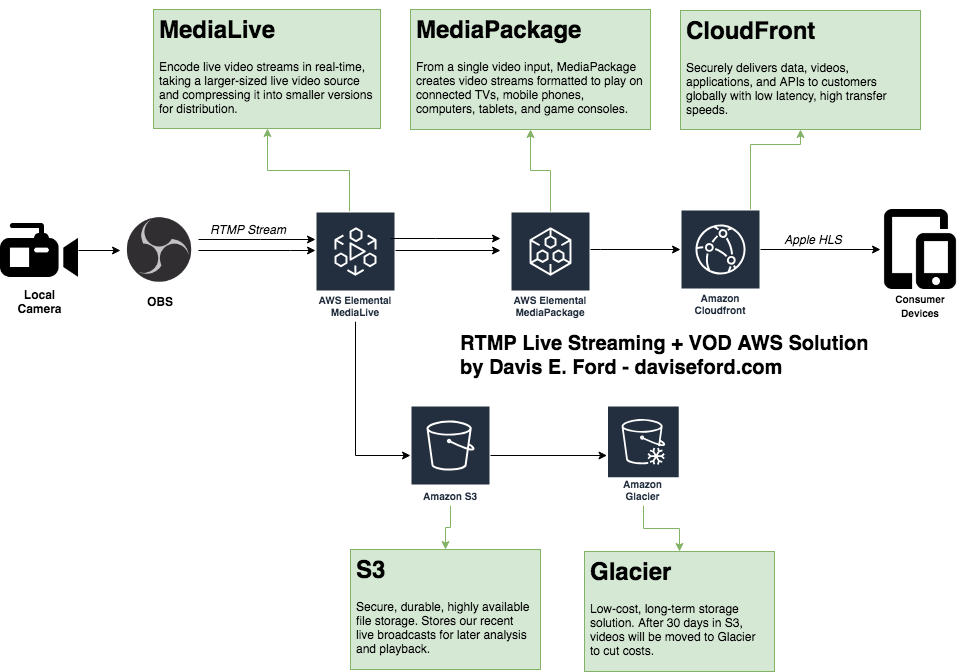
Here is my working, production design for an AWS architecture capable of receiving 360 degree panoramic 8k video via an RTMP endpoint and live-streaming at varying bitrates and resolutions to various client devices. The architecture also includes an archiving step for users that may find it necessary.
Architecture Walkthrough
- The client records stunning 360 video (preferably using a Bonsai Excalibur) and uses OpenBroadcaster Software (OBS) to stream the feed to an AWS MediaLive RTMP endpoint. MediaLive offers dual ingest - two endpoints capable of receiving the stream.
- MediaLive saves the incoming live stream to
.tsfiles in S3. This allows us to support highly durable storage of important video files. These files will later be moved to Glacier to save on storage costs. - MediaLive compresses and transcodes the incoming streaming into various output formats that will support low and high bandwidth users. Everything from 320p to 8k video is supported!
- MediaPackage uses the MediaLive channels to prepare the videos for distribution to various devices.
- The live HLS streams are available via CloudFront endpoints - using a CDN cuts down on cost, and allows us to distribute high resolution video from low latency endpoints around the world.
Note: I am working on a CloudFormation script to automatically deploy this. More to come.
AWS Advanced Networking Specialty Exam Tips and Tricks
21 Dec 2018
If you’re planning on taking the AWS Advanced Networking Specialty exam, I’ve compiled a quick list of tips that you may want to remember headed into the exam.
Note: This exam is heavily oriented towards long, detailed, and exhaustive networking questions. You cannot brute-force study your way through this exam. You need a thorough working understanding of Direct Connect and hybrid architecture scenarios and how to solve them.
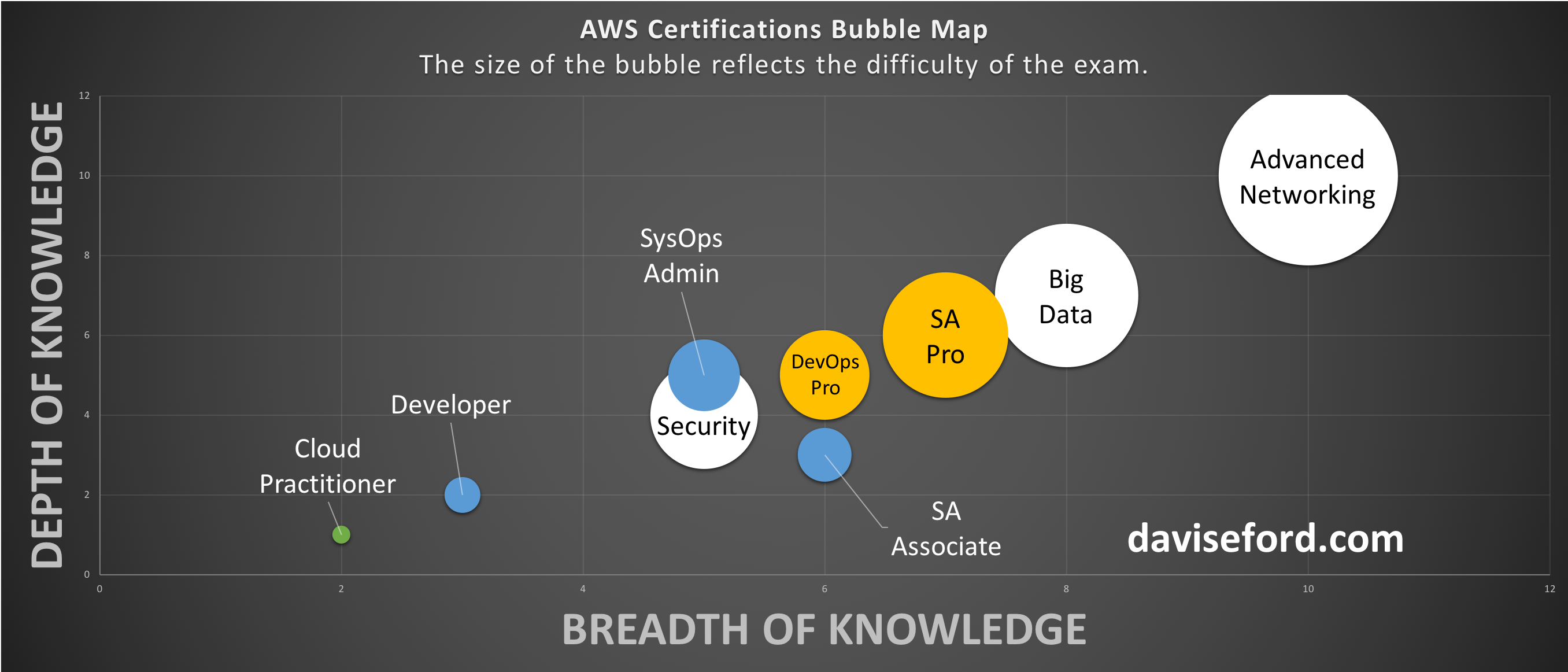
In my opinion, this exam is by far the hardest out of all AWS certifications, easily surpassing the Big Data Specialty or Solutions Architect Professional certifications for difficulty.
To give you an idea of how hard this exam really is, it’s worth noting that I currently hold all 9 AWS certifications. I had finished 8 certifications before focusing on Advanced Networking, and comfortably passed all 8 attempts. It usually takes me 30-45 minutes to sit for an AWS exam, and I generally feel extremely well-prepared when I sit down for an exam.
The first time I took Advanced Networking - Specialty, I failed with a 60% score. Unlike all of my other certification exams, I knew within the first 10 questions that my chances of passing were slim. I chewed my fingernails to bits as I tried to troubleshoot scenarios that I didn’t even know existed. I walked out of the testing center miserable - I haven’t failed a certification exam since high school (MCSE). I had wanted to get all of the AWS certifications by the end of 2018 - but AWS mandates a two-week pause before you can re-take the exam, so I would be forced to finish my goal in 2019. This stung.
But, so it goes, right? I already had eight AWS exams, and I just needed this last one. I went home and immediately scheduled the exam for two weeks later.
I wrote down all of the things that I didn’t know, and I focused on where I felt the gaps in my knowledge were. I mostly realized that my Direct Connect troubleshooting skills were terrible, and I was not very good at VPC endpoint/interface stuff.
I crammed as hard as I could. Harder than any test I have ever taken. I studied more for this test than I had ever studied in my life. I drew diagrams, flashcards, and mental maps. I had my girlfriend quiz me over and over again on CIDR block properties and subnetting math. It was not a very fun two weeks. I gained weight, avoided social contact, and thought of nothing but passing. I am not used to failing exams, and I was frustrated with myself.
I took the exam for the second time on January 5th, 2019. I passed with a 66% score.
Two weeks of effort and studying had netted me… a 6% boost in score. Luckily, AWS scores on an unpublished curve, so this was sufficient to pass.
I think the exam is so difficult for a few reasons:
- It is rare to have practical experience with Direct Connect and all of the networking concerns that accompany it.
- The core material is simply very, very dense, and requires great knowledge of a great deal of AWS services and how they interact with each other.
- You need strong networking skills in order to troubleshoot tough scenarios.
- The breadth of the exam is extreme. If you haven’t taken the Big Data certification, I doubt you will have any knowledge of some of the products that are used in the exam’s scenario questions. You need very, very broad knowledge of AWS services - on top of that, you need to be familiar with technical implementation details with them.
I found it very useful to use pen and paper to re-draw all of the various routing scenarios that are presented throughout AWS Direct Connect/VPN/VIF documentation. You need to become intimately familiar with the flow of DNS requests for different scenarios.
All that being said, I’ve laid out some of my study notes below. Please enjoy!
Scenarios
- If you need to set Active/Passive mode, use
AS_PATHprepending to make certain routes less attractive than others.- For example, if you had two DX connections and wanted to configure in an Active/Passive configuration, you should prepend the
AS_PATHof whichever DX connection you want to be the Passive.
- For example, if you had two DX connections and wanted to configure in an Active/Passive configuration, you should prepend the
- The only way AWS will prefer a VPN over Direct Connect is if the VPN has a more specific route table entry.
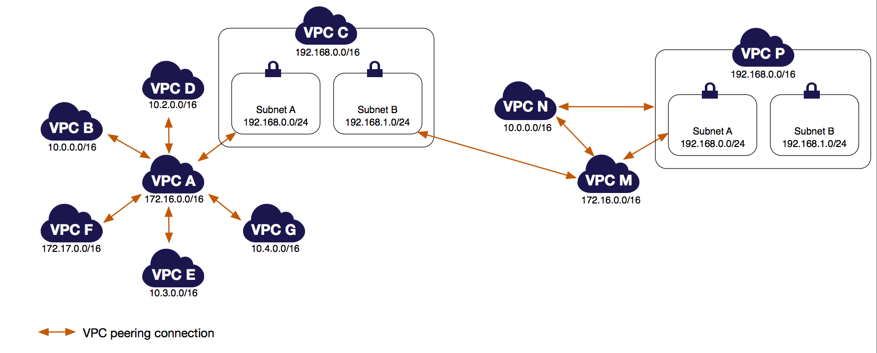
Credit: ToTheNew.com for the diagram.
- Read this article in its entirety: VPC Peering Configurations with Specific Routes. You need to understand how to adjust your route tables for various VPC Peering scenarios.
DNS
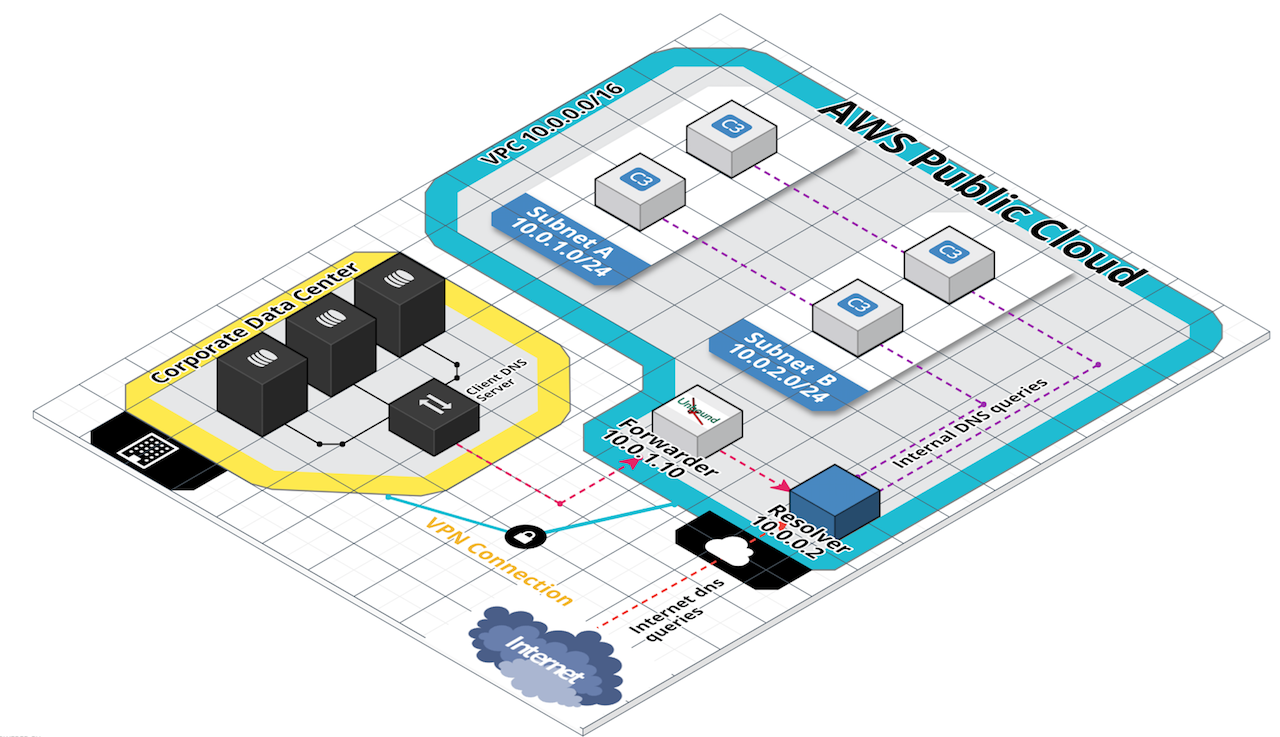
- Configure your custom DNS servers on EC2 instances in your VPC to route your private DNS queries to the IP address of the Amazon-provided DNS servers for your VPC. This IP address is the IP address at the base of the VPC network range “plus two.” If your VPC CIDR block is
10.0.0.0/16, the IP address of the DNS server is10.0.0.2. (Source) - If you’re using custom DNS servers that are outside of your VPC and you want to use private DNS, you must use custom DNS servers on EC2 instances within your VPC.
- If you have integrated your on-premises network with one or more VPC virtual networks and you want your on-premises network to resolve domain names in private hosted zones, you can create a Simple AD directory. Simple AD provides IP addresses that you can use to submit DNS queries from your on-premises network to your private hosted zone.
- You cannot further subnet a
/28CIDR block. - DNS servers require TCP/UDP port 53 to be open.
- For each public hosted zone that you create, Amazon Route 53 automatically creates a name server (NS) record and a start of authority (SOA) record. Don’t change these records.
BGP
- BGP is typically classified as a path vector protocol.
- A path vector protocol is a network routing protocol which maintains the path information that gets updated dynamically. (Source)
Routing
AS_PATHprepending assists in setting Active/Passive mode.- Keep these route preference rules in mind. They are evaluated from the top down.

MED values and the shortest AS_PATH are preferred!Credit: ACloudGuru.com for the slide.
- Bidirectional Forwarding Detection (BFD) is a network fault detection protocol that provides fast failure detection times, which facilitates faster re-convergence time for dynamic routing protocols. Enable BFD when configuring multiple DX connections or a single DX + VPN backup. You can configure BFD to detect failures and update dynamic routing as Direct Connect quickly terminates BGP peering so that backup routes can kick in. (Source)
- A forwarding equivalence class (FEC) is a term used in Multi-protocol Label Switching (MPLS) to describe a set of packets with similar or identical characteristics which may be forwarded the same way. An FEC label is used by the router to know where to forward packets in an MPLS network. (Source)
- DSCP can be used as a means of classifying and managing network traffic and of providing QoS in modern Layer 3 IP networks. (Source)
- Make sure to allow ephemeral ports in your outbound NACL rules.
VPCs
- The default VPC can be deleted and recreated.
- Broadcasting is not allowed by AWS.
Direct Connect
- AWS will always prefer a DX connection over VPN, unless the VPN has a more specific route.
- A sub-1Gbps connection is indicative of a hosted connection.
- A VIF is required for each VPC connected to the DX connection.
- You cannot change the port speed of a connection after creation.
- There is a limit of 100 advertised BGP routes. Summarize routes if you have more than this.
- Study the Direct Connect troubleshooting tips.
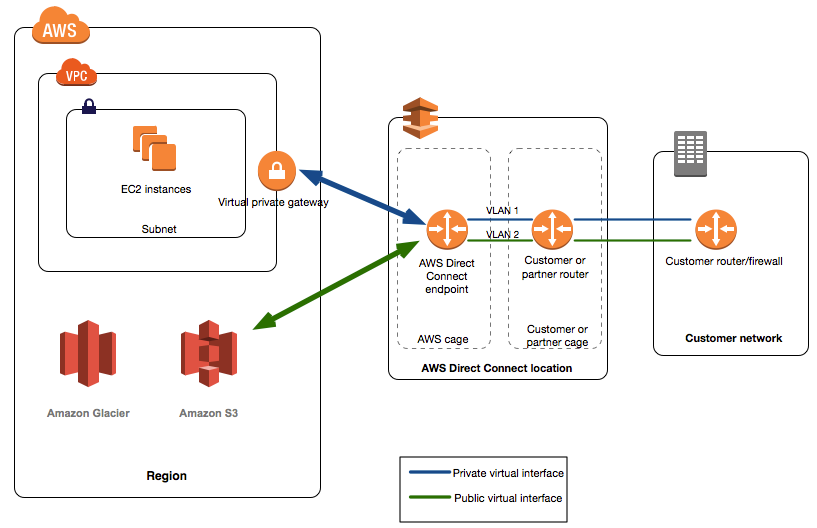
- A Direct Connect Gateway is a grouping of VGW’s and private VIFs that belong to the same account.
- Read through this great resource on Direct Connect Gateways.
- Remember: The VPCs to which you connect through a Direct Connect gateway cannot have overlapping CIDR blocks.
- DX Gateway is a global service.
- Cannot be used cross account. Cannot be used with public VIFs.
- Cannot be used to send traffic to other VPCs that are connected to the same Gateway.
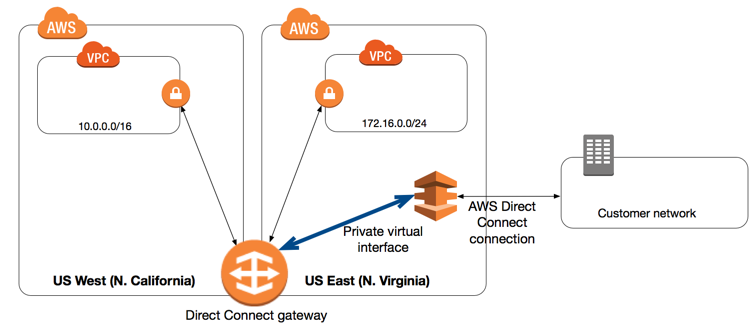
- You may be asked how many LOA’s will be generated for a customer request. Remember the formula:
1 LOA per Connection per Datacenter.- A Link Aggregation Group (LAG) counts as one LOA.
Direct Connect Requirements
I noticed that the exam had an unusual emphasis on the Direct Connect requirements. Make sure you know these requirements by heart. It’ll be worth a few points on the exam.
- BGP
- BGP MD5 authentication
- 802.1Q VLAN encapsulation
- Single-mode fiber with a 1000BASE-LX (1310nm) transceiver for 1gb Ethernet or a 10GBASE-LR (1310nm) transceiver for 10gb Ethernet.
- Auto-negotiation for the port must be disabled.
- Port speed and full-duplex mode must be configured manually.
VPNs
- AWS will always prefer a DX connection over VPN, unless the VPN has a more specific route.
- Use an IPSec VPN over a public VIF to ensure protection of your data en-route from your on-premise datacenter.
- AWS VPN does not support 128 bit AES encryption.
- You need to use a public VIF over a DX connection in order to use an IPSec VPN.
- You can monitor your VPN tunnels using Cloudwatch. (Source)
- There are three VPN metrics:
TunnelState,TunnelDataOut, andTunnelDataIn. - Use
aws cloudwatch list-metrics --namespace "AWS/DX"to view metrics using the CLI.
- There are three VPN metrics:
- If the VPN connection is idle for 10 seconds, the connection may close. Use a keep-alive tool to send continuous traffic.
- Static routes take priority over propagated routes - it’s assumed that you’re using static routes for a good reason.
- The VPN tunnel comes up when traffic is generated from your side of the Site-to-Site VPN connection. The virtual private gateway is not the initiator; your customer gateway must initiate the tunnels. (Source)
- Allow UDP 500 (and UDP 4500 if using NAT Traversal).
OSI Layers Cheatsheet
- Application - DNS, DHCP, BGP, FTP, SMTP
- Network/Internet - IPSec
- Transport - TCP/UDP
Protocol/Port Cheatsheet
- IPSec: IP 50, UDP 500
- VPN: UDP 500, UDP 4500 for NAT-Traversal
- DNS: TCP/UDP 53
- Ephemeral Port Range: 1024-65535
Elastic Load Balancers
- ELB needs a minimum subnet size of
/27(not/28). - ELB SSL Negotiation: A security policy is a combination of:
- SSL protocols
- SSL ciphers
- Server Order Preference option.
- ELB SSL Negotiation:
SSL 2.0has been deprecated. UseSSL 3.0,TLS 1.0,TLS 1.1, orTLS 1.2.
CIDR Blocks and Subnetting
- You need to understand CIDR blocks, addresses ranges, and be able to do subnet math in your head on the fly. Use this calculator to get better at subnetting.
- The minimum size of a VPC subnet is a
/28(16 addresses) for IPv4. - The maximum size is a
/16(65,535 addresses). - For IPv6, the VPC is a fixed size of
/56. - Use the
10.0.0.0/8,172.16.0.0/12and192.168.0.0/16ranges. (Source)- For IPv6, the subnet size is fixed to be a /64. Only one IPv6 CIDR block can be allocated to a subnet.
- The default VPC range is
172.31.0.0/16 - Remember that 5 addresses are reserved per subnet:
- 0 - Network address
- 1 - VPC router
- 2 - DNS
- 3 - Reserved by AWS for future use
- 255 - Broadcast
- Subnets cannot be larger than the VPC in which they are created.
Enhanced Networking and Performance
- You can only use Jumbo frames/high MTU values within a VPC - once the traffic leaves the VPC, use 1500 MTU. The only exception to this is VPC peering traffic - it can take advantage of 9001 MTU. (Source)
- To maximize instance speed for an external/internal facing instance, attach two ENIs:
- An externally-facing ENI with an MTU of 1,500 bytes
- An internally-facing ENI with an MTU of 9,001 bytes
- DPDK is the Data Plane Development Kit. It consists of libraries to accelerate packet processing workloads running on a wide variety of CPU architectures.
- General Rules of Placement Groups: (Source)
- The name you specify for a placement group must be unique within your AWS account for the Region.
- You can’t merge placement groups.
- An instance can be launched in one placement group at a time; it cannot span multiple placement groups.
- Instances with a tenancy of host cannot be launched in placement groups.
- Use spread placement groups when you are aiming for high availability.
- Use cluster placement groups when high performance is your only concern.
Public and Private VIFs
- General VIF Creation Requirements:
- Name
- Owner
- Connection
- VLAN ID
- BGP Information
- ASN
- BGP MD5 key
- Peer IP’s
- Public VIFs: Choose which prefixes to advertise
- Private VIFs: Jumbo Frame setting
- You really need to understand public vs. private VIF’s, hosted VIF’s, Direct Connect Gateways, IPSec VPN’s, and how all of them interact.
- What are the differences between public virtual interfaces and private virtual interfaces for Direct Connect?
- Public Virtual Interface
- To connect to AWS public endpoints, such as DynamoDB or S3, with dedicated network performance, use a public VIF.
- Use an IPSec VPN over a public VIF to ensure protection of your data en-route from your on-premise datacenter.
- Private Virtual Interface
- To connect to private services, such as a VPC, with dedicated network performance, use a private VIF.
- A private VIF allows you to connect to your VPC resources on your private IP address or endpoint. A private VIF can connect to a DX gateway, which can be associated with one or more VGWs.
- A virtual private gateway is associated with a single VPC, so you can connect to multiple VPCs using a private VIF. For a private VIF, AWS only advertises the entire VPC CIDR over the BGP neighbor.
- Public Virtual Interface
- What are the differences between public virtual interfaces and private virtual interfaces for Direct Connect?
- Do not advertise more than 100 prefixes for private virtual interfaces or 1,000 prefixes for public virtual interfaces. These are hard limits and cannot be exceeded. (Source)
VPC Endpoints
- You cannot extend endpoint functionality outside of the VPC - this means you cannot access a VPC endpoint from another location (like a VPC peer, or over a VPN).
- DNS resolution is required within the VPC.
- Default VPCE policy is unrestricted. You can lock it down after creation.
- You can’t reach VPC endpoints over a private VIF.
Link Aggregation Groups
- All connections in a LAG run in an Active/Active configuration. LAG is a Layer 2 connection. (Source)
- Remember the three rules of creating Link Aggregation Groups:
- All connections in the LAG must use the same bandwidth.
- You can have a maximum of four connections in a LAG. Each connection in the LAG counts towards your overall connection limit for the Region.
- All connections in the LAG must terminate at the same AWS Direct Connect endpoint.
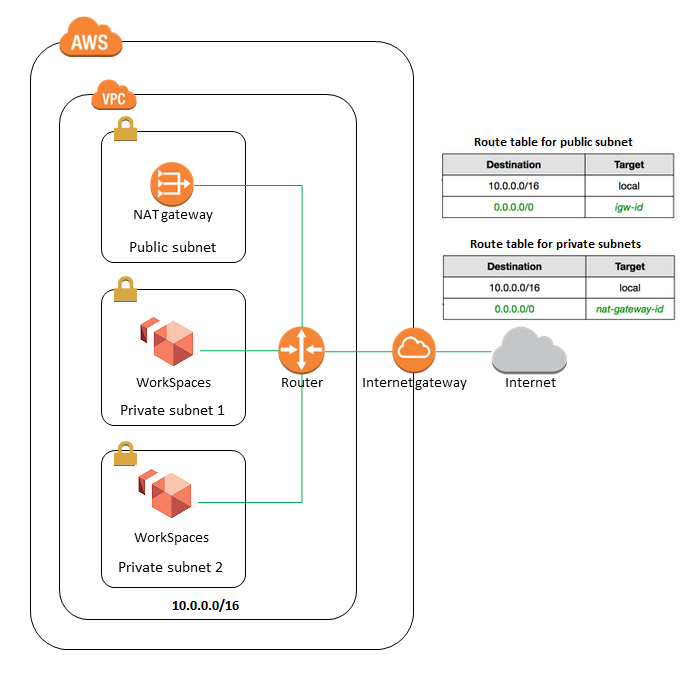
Workspaces
- Remember that AWS Workspaces requires a minimum of 1200 MTU. (Source)
Route53
- Use Route53 to configure split-view DNS, also known as “split-horizon DNS”. This feature can be used when you want to maintain internal and external versions of the same website or application. (Source)
- Create a Reusable Delegation Set using the Route 53 API command
CreateReusableDelegationSet(you can’t do this through the AWS console) if you want to re-use nameservers across different hosted zones.
Cloudhub
- The hub and spoke model involves creating multiple Customer Gateways, each with a public IP address.
- The remote network prefixes for each spoke must have unique ASNs, and the sites must not have overlapping IP ranges.
Cloudwatch
- Use Lambda@Edge in conjunction with Cloudwatch to perform actions based on incoming requests. For example:
- A Lambda function can inspect cookies and rewrite URLs so that users see different versions of a site for A/B testing.
- CloudFront can return different objects to viewers based on the device they’re using by checking the User-Agent header, which includes information about the devices.
- On a retail website that sells clothing, if you use cookies to indicate which color a user chose for a jacket, a Lambda function can change the request so that CloudFront returns the image of a jacket in the selected color.
- Generate HTTP responses when CloudFront viewer request or origin request events occur.
- inspect headers or authorization tokens, and insert a header to control access to your content before CloudFront forwards the request to your origin.
- Make network calls to external resources to confirm user credentials, or fetch additional content to customize a response.
Security Groups and Network Access Control Lists
- In case of a DDOS, the fastest way to stop incoming requests is to delete the default NACL in a VPC.
- You cannot apply Security Groups to NAT Gateways or Egress-Only Gateways (which makes sense, because you can’t set outgoing rules with Security Groups anyways!)
Misc
- Know your basic service limits:
- Max. 5 Internet Gateways per region
- Direct Connect: 100 BGP advertised routes per route table maximum
- You need to assign an Elastic IP to NAT Gateways.
- Use
tracepathto check MTU between two hosts.tracepathneeds UDP traffic allowed in order to function. - A hosted VIF is a VIF created on your Direct Connect connection, and shared with another AWS account.
- By contrast, a hosted connection is a sub-1gbps connection allocated by an AWS partner for your use.
Training Materials I Used
- ACloudGuru - AWS Advanced Networking Specialty Course
- WhizLabs Practice Exams (None of these questions appear on the exam, but they do get you valuable practice with AWS-style questions)
Whitepapers I Read
- Hybrid Cloud DNS Solutions for Amazon VPC
- Amazon VPC Connectivity Options
- Integrating AWS with Multiprotocol Label Switching (MPLS)
Videos I Watched
- AWS re:Invent 2016: Elastic Load Balancing Deep Dive and Best Practices (NET403)
- AWS re:Invent 2017: Deep Dive: AWS Direct Connect and VPNs (NET403)
- AWS re:Invent 2016: Extending Datacenters to the Cloud (NET305)
- AWS re:Invent 2017: Creating Your Virtual Data Center: VPC Fundamentals (NET201)
- AWS re:Invent 2016: DNS Demystified: Amazon Route 53, featuring Warner Bros. (NET202)
- What is the difference between a hosted VIF and hosted connection when using AWS Direct Connect?
- Why is IKE (phase 1 of my VPN tunnel) failing in Amazon VPC?
Other Links
- Online CIDR Calculator
- VPC Peering Configurations with Routes to an Entire CIDR Block
- Route Tables and VPN Route Priority
- Network Maximum Transmission Unit (MTU) for Your EC2 Instance
- DX: Accessing a Remote AWS Region
- Wikipedia: Internet Protocol suite
- Connecting a Single Customer Router to Multiple VPCs
- Route53: Working with Private Hosted Zones
- Unsupported VPC Peering Configurations
- Reviewing DNS Mechanisms for Routing Traffic and Enabling Failover for AWS PrivateLink Deployments
- How to Set Up DNS Resolution Between On-Premises Networks and AWS by Using Unbound
- DNS Resolution Between On-Premises Networks and AWS Using AWS Directory Service and Microsoft Active Directory
AWS Big Data Specialty Exam Tips and Tricks
05 Dec 2018
If you’re planning on taking the AWS Big Data Specialty exam, I’ve compiled a quick list of tips that you may want to remember headed into the exam.
I passed the exam on December 6, 2018 with a score of 76%. In my opinion, this exam is more difficult than the AWS Solutions Architect Pro!
- You really, really need to understand Redshift distribution strategies. Here are some things to remember:
- Automatic Distribution: The default option, Redshift automatically manages your distribution strategy for you, shifting from an initial
ALLstrategy (for smaller tables) toEVENdistribution (for larger tables). Note: Redshift will not automatically switch back fromEVENtoALL. - Even Distribution: With the
EVENdistribution, the leader node distributes rows equally across all slices. This is appropriate for tables that do not participate in joining. - Key Distribution: With the
KEYdistribution, rows are distributed according to a selected column. Tables that share common join keys are physically co-located for performance. - All Distribution: A copy of the entire data set is stored on each node. This slows down inserting, updating, and querying. This distribution method is only appropriate for small or rarely-updated data sets.
- Automatic Distribution: The default option, Redshift automatically manages your distribution strategy for you, shifting from an initial
- You need to know the DynamoDB partition sizing formula by heart:
(Desired RCU/3000 RCU) + (Desired WCU/1000 RCU) = # of partitions needed - AWS Machine Learning does not support unsupervised learning - you will need Apache Spark or Spark MLLib for real-time anomaly detection.
- AWS IoT accepts four forms of identity verification: X.509 certificates, IAM users/roles, Cognito identities, and Federated identities. “Typically, AWS IoT devices use X.509 certificates, while mobile applications use Amazon Cognito identities. Web and desktop applications use IAM or federated identities. CLI commands use IAM.”
- In the context of evaluating a Redshift query plan,
DS_DIST_NONEandDS_DIST_ALL_NONEare good. They indicate that no distribution was required for that step because all of the joins are co-located. DS_DIST_INNERmeans that the step will probably have a relatively high cost because the inner table is being redistributed to the nodes.DS_DIST_ALL_INNER,DS_BCAST_INNERandDS_DIST_BOTHare not good. (Source)- You must disable cross-region snapshots for Redshift before changing the encryption type of the cluster.
- Amazon recommends allocating three dedicated master nodes for each production ElasticSearch domain.
- Read up on DAX and DynamoDB.
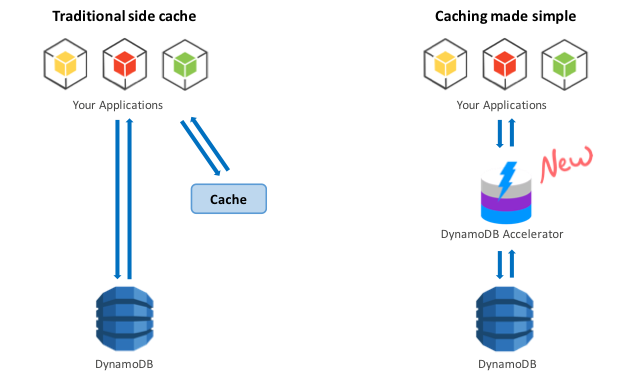
- DynamoDB: Remember to use “write sharding” to allow writes to be distributed evenly across partitions. There are two methods for this: Random Suffixes and Calculated Suffixes.
- A Kinesis data stream retains records for 24 hours by default, but this can be extended to 168 hours using the
IncreaseStreamRetentionPeriodoperation. - To make your data searchable in CloudSearch, you need to format it in JSON or XML.
- You can use popular BI tools like Excel, MicroStrategy, QlikView, and Tableau with EMR to explore and visualize your data. Many of these tools require an ODBC (Open Database Connectivity) or JDBC (Java Database Connectivity) driver. (Source)
- Hue is the web interface for an EMR cluster.
- The following are some fantastic slides from the invaluable AWS re:Invent 2017: Big Data Architectural Patterns and Best Practices on AWS (ABD201) talk. Watch it two or three times.
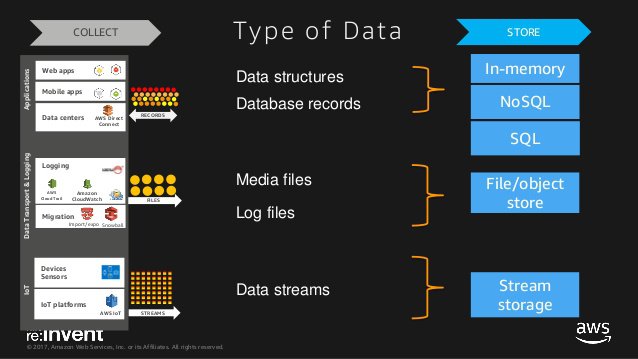
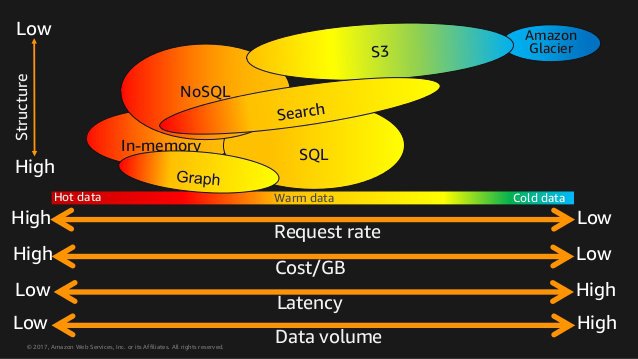


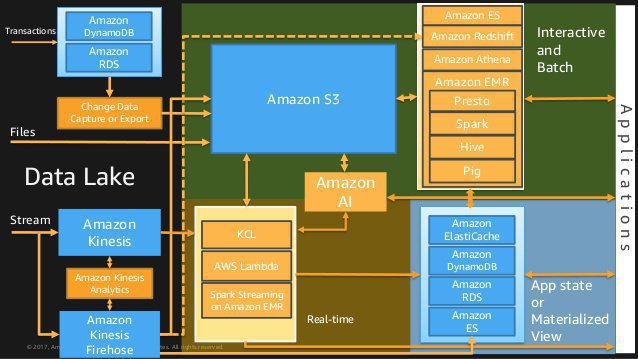
- After a Redshift load operation is complete, query the
STL_LOAD_COMMITStable to verify that the expected files were loaded. - Mahout is a machine learning library with tools for clustering, classification, and several types of recommenders, including tools to calculate most-similar items or build item recommendations for users. Use it to carry out Machine Learning work on top of Hadoop.
- When preparing to use a Lambda/Kinesis combination, make sure to optimize your Lambda memory and batch size, and adjust the number of shards used by the Kinesis streams.
- Triggers do not exist in Redshift.
- Amazon Kinesis Aggregators is a Java framework that enables the automatic creation of real-time aggregated time series data from Kinesis streams. (Source)
- You can’t encrypt an existing DynamoDB table. You need to create a new, encrypted table and transfer your data over. (Source)
- Presto is a fast SQL query engine designed for interactive analytic queries over large datasets from multiple sources. (Source)
- Redshift creates the following log types:
- Connection log — logs authentication attempts, and connections and disconnections.
- User log — logs information about changes to database user definitions.
- User activity log — logs each query before it is run on the database.
- Kinesis Data Firehose can send records to S3, Redshift, or Elasticsearch. It cannot send records to DynamoDB. (Source)

- Use Spark for general purpose Amazon EMR operations, use Presto for interactive queries, and use Hive for batch operations.
- Use Athena generally to query existing data in S3. You should be aware that Redshift Spectrum exists, and that it can query data in S3.
- If a question is asking how to handle joins or manipulations on millions of rows in DynamoDB, there’s a good chance that EMR with Hive is the answer.
- When using Spark, you should aim for a memory-optimized instance type.
- To improve query performance and reduce cost, AWS recommends partitioning data used for Athena, and storing your data in Apache Parquet or ORC form - not .csv!
- Use the
COPYcommand to transfer data from DynamoDB to Redshift. UseUNLOADto transfer the results of a query from Redshift to S3. - Redshift clusters have two types of nodes:
Leadernodes andComputenodes.
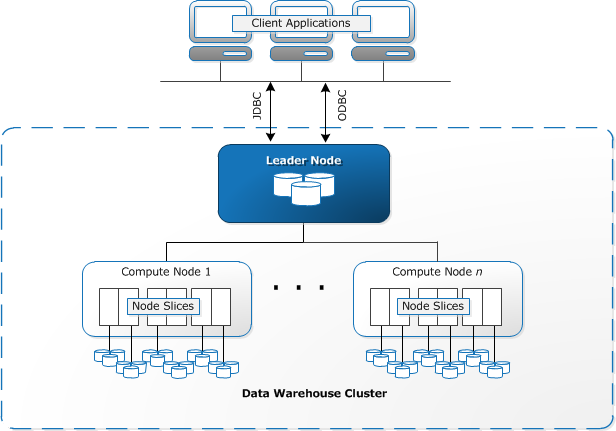
Leader node goes down, the cluster health will suffer.- Not to be confused with EMR, which uses
Master,Core, andTasknodes.
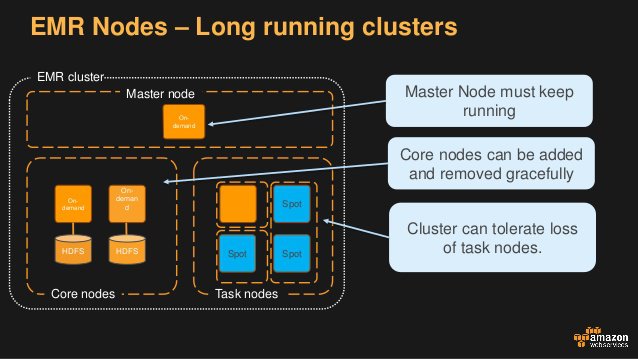
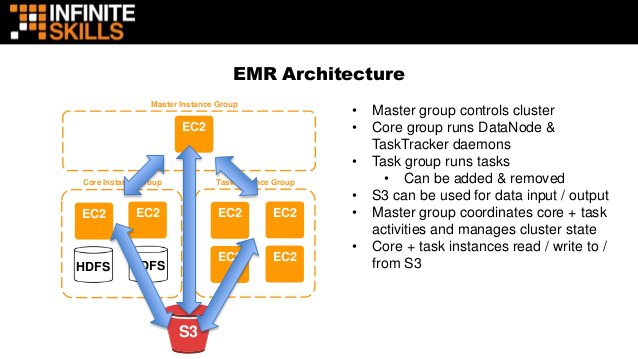
Master node by default.- Use ElasticSearch to analyze data stream updates from other services, such as Kinesis Streams and DynamoDB.
- Amazon Schema Conversion Tool is sometimes referred to as SCT.

Training Materials I Used
- ACloudGuru - AWS Big Data Specialty Course
- WhizLabs Practice Exams (None of these questions appear on the exam, but they do get you valuable practice with AWS-style questions)
Whitepapers I Read
- Comparing the Use of Amazon DynamoDB and Apache HBase for NoSQL
- Lambda Architecture for Batch and Stream Processing
- Enterprise Data Warehousing on AWS
Other Links
- Top 8 Best Practices for High-Performance ETL Processing Using Amazon Redshift
- Glacier Expedited, Standard, and Bulk Retrieval Types
- Redshift Engineering’s Advanced Table Design Playbook
- QuickSight FAQ
- Server-Side Encryption for Kinesis Data Streams
- Amazon EMR - Submit a Streaming Step
- Redshift - Choosing the Best Sort Key
- Capturing Table Activity with DynamoDB Streams
- Redshift: Choosing the best Distribution model
- Visualize AWS Cloudtrail Logs Using AWS Glue and Amazon QuickSight
- Redshift: Vacuuming Tables
- Analyze Apache Parquet optimized data using Kinesis Data Firehose, Athena, and Redshift
- Building a Binary Classification Model with Machine Learning and Redshift
- AWS IoT Authentication
- Use Business Intelligence Tools with EMR
- JOIN Redshift AND RDS PostgreSQL WITH dblink
- Ensuring Consistency When Using S3 and Elastic MapReduce for ETL Workflows
AWS DevOps Engineer Professional Exam Tips and Tricks
30 Nov 2018
If you’re planning on taking the AWS DevOps Engineer Professional exam, I’ve compiled a quick list of tips that you may want to remember headed into the exam.
I passed the exam on November 30th, 2018. Before taking this exam, I had already achieved my SA Pro. There is a fair amount of overlap between the two tests - I would highly recommend taking the SA Pro before this exam. I scored an 85% on the exam.
This exam is fairly difficult, although I would argue it’s slightly easier than the Solutions Architect Professional exam. There is a greater focus on implementation and debugging in the DevOps exam - the SA Pro exam is more about breadth of knowledge across AWS services.
- Remember to solve exactly what the question is asking. If they want performance, give them read replicas, sharding, PIOPS, etc. If they want elasticity and high availability, start using Multi-AZ, cross-region replication, Auto Scaling Groups, ELB’s, etc. If they are worried about cost, remember the S3 storage classes, and use AutoScaling groups to scale down unnecessary instances.
- The basic stages of a Continuous Integration pipeline are
Source Control->Build->Staging->Production. - ELB can be configured to publish logs at a 5 or 60 minute interval. Access logs are disabled by default.
- When an instance is launched by Autoscaling, the instance can be in the
pendingstate for up to 60 minutes by default. - Cloudwatch logs can be streamed to Kinesis, Lambda, or ElasticSearch for further processing.
- The fastest deployment times in Elastic Beanstalk are achieved using the
All At Oncedeployment method. - Remember this Opswork trivia: “For Linux stacks, if you want to associate an Amazon RDS service layer with your app, you must add the appropriate driver package to the associated app server layer”
- Generally, if you see Docker, think Elastic Beanstalk!
- AWS OpsWorks Stacks agents communicate regularly. If an agent does not communicate with the service for more than approximately five minutes, AWS OpsWorks Stacks considers the instance to have failed.
- You can configure an Opswork stack to accept custom cookbooks after creation. Just enable the option.
- Speaking of custom cookbooks, remember that the custom cookbook option is enabled at the stack level, not the layer level.
- The CodeDeploy service relies on a
appspec.ymlfile included with your source code binaries on an EC2/On-Premises Compute Platform. - A nested stack is a stack that you create within another stack by using the
AWS::CloudFormation::Stackresource. - When attempting to secure data in transit through an ELB, remember you can use either an HTTPS or SSL listener.
- AWS CodeDeploy can deploy application content stored in Amazon S3 buckets, GitHub repositories, or Bitbucket repositories. Note: Subversion is not supported.
- CodeDeploy offers two deployment types: In-place deployment and Blue-Green deployment.
- A
Dockerrun.aws.jsonfile is an Elastic Beanstalk–specific JSON file that describes how to deploy a set of Docker containers as an Elastic Beanstalk application. - This exam is extremely tough to parse at first glance. There are lots of grammatical twists and turns that are not present in typical exams. You may need to check your proposed architecture against the question 4-5 times to ensure that you are solving the right problem.
- Remember to use the
NoEchoproperty in CloudFormation templates to prevent adescribecommand from listing sensitive values, such as passwords. - You really need to understand the lifecycle of an EC2 instance (pictured below) being brought into service.
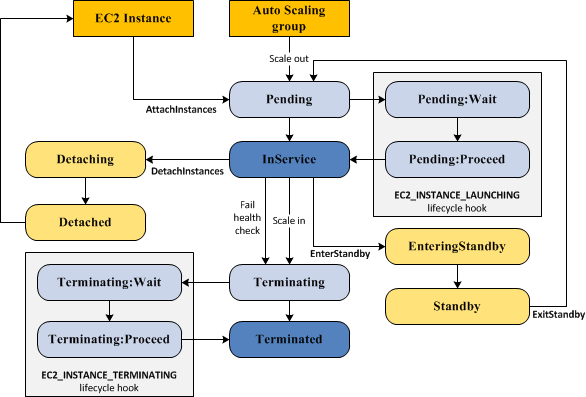
Training Materials I Used
Whitepapers I Read
- Practicing Continuous Integration and Continuous Delivery on AWS
- Blue/Green Deployments on AWS
- Strategies for Managing Access to AWS Resources in AWS Marketplace
Other Links
- Running Docker on AWS OpsWorks
- AWS CodeDeploy Primary Components
- Automating the Amazon EBS Snapshot Lifecycle with Amazon Data Lifecycle Manager
cfn-signalExamples- Creating Wait Conditions in a Template
- CreationPolicy Attribute
- ELB: Customizing Software on Windows Servers
- A helpful Medium article with more exam tips