AWS Solutions Architect Professional Exam Tips and Tricks
26 Nov 2018
If you’re planning on taking the AWS Solutions Architect Professional exam, I’ve compiled a quick list of tips that you may want to remember headed into the exam.
I passed the exam on November 24th, 2018. Before taking this exam, I held all three Associate certifications and the Security Specialty certification. I passed with an 80% score, and it took 69 minutes.
This exam is very difficult - on par with the Security Specialty exam! You will not accidentally pass this exam. :)
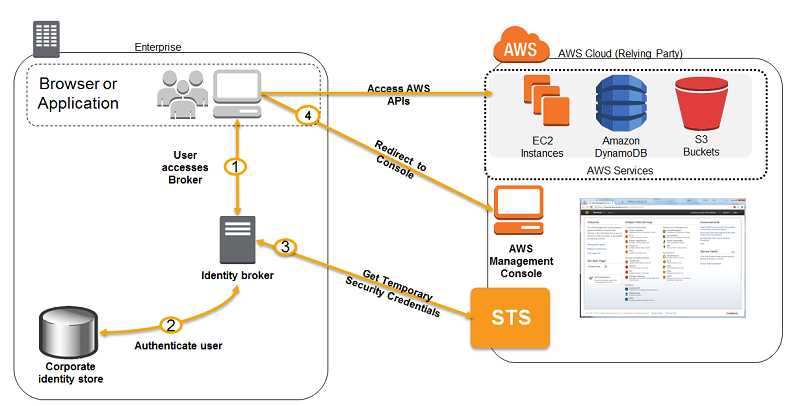
- You need to know your STS use cases inside and out. Remember that you generally need to develop an identity broker, your application will authenticate against LDAP or your broker, and then against STS. Your application will not directly authenticate against STS first!
- Understand how cross-account access, and granting that access, works.
- Remember to turn on the Cloudtrail “global services” in order to track IAM usage.
- Prefer Cloudformation for version controlled infrastructure configuration.
- You need to understand what BGP does (and what it doesn’t do) in relation to Direct Connect. The ACloudGuru course did not cover eBGP or weighting policies very heavily, so you will need to do additional research. I recommend watching this video before taking the exam.
- Use SQS queues placed in front of RDS/DynamoDB to reduce the load on your databases!
- Use Kinesis for large amounts of incoming data, especially when it’s coming from multiple sources.
- Any time you see the words “mobile app”, “social networking login”, “Login with Amazon”, or “Facebook” on the exam, you should immediately be able to narrow down the answers - hint: the correct answer will probably involve Web Identity Federation.
- Play around with this CIDR calculator if you have trouble understanding VPC/subnet CIDR ranges and possibilities. Always remember that AWS reserves five IP addresses for their use (first four IP’s and the last IP).
- There are usually two blatantly incorrect answers, and two answers that could be right. Narrow down your choices.
- Understand the various best practices for encrypting data at rest and in transit.
- You need to understand public VIF’s vs. private VIF’s, and which services use which type of VIF.
- You need to understand ELBs, Auto Scaling, and how to architect a scalable architecture. By this point in your AWS studies (assuming you already have an Associate certificate), you should have this pretty down pat. I recommend watching this video for a cool overview of setting up low latency multiplayer servers globally.
- Even though Data Pipeline has been pretty much usurped by Lambda, it features fairly heavily on the exam. Definitely watch the ACloudGuru videos on Data Pipeline (and follow the labs) before taking the exam.
- AWS Connector for vCenter shows up in one or two questions, and is worth knowing about.
- You need to know the different instance types and what usage scenarios are appropriate for them. Remember that if you receive a capacity error when resizing a placement group, you just need to stop and restart the placement group - this will allocate the group to a new physical cluster with a proper amount of instances.
Training Materials I Used
- ACloudGuru - AWS Solutions Architect Professional Course
- WhizLabs Practice Exams
- Braincert Practice Exams
Videos I Watched (in order of importance)
- AWS re:Invent 2016: (NET402) Deep Dive: AWS Direct Connect and VPNs
- AWS re:Invent 2014: (GAM402) Deploying a Low-Latency Multiplayer Game Globally: Loadout
- AWS re:Invent 2014: (BAC404) Deploy High Availability & Disaster Recovery Architectures with AWS
Whitepapers I Read
Other Links
- Interactive CIDR Calculator
- What is AWS Direct Connect?
- Using IAM Roles
- HTTP Headers and Classic Load Balancers
- AWS Data Pipeline FAQ
- Amazon SNS Mobile Push High-Level Steps
- AWS Database Migration Service
- AWS Server Migration Service
- AWS Cloud Data Migration
- AWS Management Portal for vCenter Server
- Classic Load Balancers vs. Application Load Balancers
- Migrating Your Virtual Machine to Amazon EC2 Using AWS Connector for vCenter
- A useful thread on ACloudGuru from people who have taken the exam
React Conf '18 - I'm Hooked
28 Oct 2018
I am flying home from React Conf 2018, hosted at the Westin Hotel in Lake Las Vegas. Some of the key takeaways of this year’s conference:

Hooks are coming
The conference started out strong with Dan Abramov demonstrating new React hooks to the crowd. I heard many, many audible gasps from the crowd as Dan walked us through using hooks to replace traditional React classes. I had the feeling that I was watching a new version of React being demoed right before our eyes. Although the API is unstable and experimental at this point (it’s just an RFC right now), it is immediately clear that this is the future of React. I am very grateful I was there to hear the announcement in person.
So, what are hooks going to do for you? Well, first of all, you’re going to be writing a lot less boilerplate class code. React 16.7 (alpha) allows us to use functions rather than classes as our components.
State management will be handled by React’s useState (docs) function - I will say that I felt a little strange about the ergonomics of useState (you have to call it sequentially, ordering matters). I think that for complex components that require lots of state updates, I would still write traditional classes. This useState pattern seems best suited for simpler components that only hold a couple values in state.
Instead of manually tracking side effects of components using componentDidMount and componentWillUnmount we can use (no pun intended) the new useEffect (docs) functions that React provides in 16.7 Alpha. This is probably the most promising feature I saw from Dan Abramov’s presentation.
Rather than segmenting application logic throughout these various lifecycle components:
componentDidMount(){
// Do something here because we mounted our component
add_event_listener('foo_event')
}
componentWillUnmount() {
// Make sure we unload whatever we did when we mounted!
remove_event_listener('foo_event')
}We will now be able to import the useEffect function and use it like this:
export default function () {
useEffect(() => {
// Do a thing here.. maybe add an event listener
add_event_listener('foo_event')
// If we want the event listener to be removed when our component is unmounted
// We just need to return an anonymous function containing the actions we want performed
return () => {
remove_event_listener('foo_event')
}
)
}That’s really it. It may seem a bit magical (it certainly feels like it), but React will now perform the same duties that it used to, but with all of the logic nicely grouped together! This makes writing and debugging side effects much easier.
One more big change.
One of the worst parts of React was dealing with boilerplate code, particularly when it comes to shouldComponentUpdate. shouldComponentUpdate is rarely used for much more than checking if the prevProps != nextProps based on some criteria.
This is some very typical shouldComponentUpdate boilerplate that I’m sure you’re familiar with:
shouldComponentUpdate(nextProps) {
if (this.props.id !== nextProps.id) {
return true
}
return false
}We are just checking if the incoming props have a different id than the props we already have. This is a fairly standard check for a lot of React components. What if React could just diff our props for us, and only update when necessary?
// Example taken from https://reactjs.org/docs/hooks-reference.html#conditionally-firing-an-effect
useEffect(
() => {
const subscription = props.source.subscribe();
return () => {
subscription.unsubscribe();
};
},
[props.source], // Only run if the props.source values changes
);Did I mention that when you use function components, there is no more binding to this? That alone is a compelling reason to begin exploring using React Hooks.
React Native isn’t there… yet
I really enjoyed James Long’s talk “Go Ahead, Block the Main Thread”, where he argued against a lot of common wisdom regarding Javascript. James talked about the viral impact of async functions - once a single function is async, everything in the codebase eventually follows suit. That’s never personally been a problem for me (I greatly enjoy using the asynchronous features of JS).
James argued that the asynchronous nature of React Native’s interaction with native API’s was harming UX. He showed some compelling examples of janky scrolling behavior that occurs when the React Native asynchronous processes fall behind the screen render.

His solution: Block the main thread. Don’t let other tasks interrupt crucial animation rendering. What’s the best way to do that? Get rid of async, and allow synchronous flow between native API’s and React Native.
GraphQL is in vogue
Speaking of talks I enjoyed, I greatly enjoyed Conor Hasting’s talk about GraphQL.

In a typical REST API setup, a consumer requests data from an endpoint. The consumer has little to no control over what is delivered to them. To use Conor’s analogy, it’s like calling a pizza parlor for pizza delivery, and since they don’t know what toppings you like, they put 40 different toppings on the pizza, deliver it to your house, and tell you to pick off the ingredients you don’t like.
When you’re working on a front-end application and constantly consuming API’s for varying amounts of data, this can get exhausting. Want to get only the id and timestamp of a given set of rows? Too f’ing bad. Now your front-end application is stuck having to munge, filter, and extract data, even though we know exactly what we want. It’s like calling the pizza parlor, asking for pepperoni, and getting 40 toppings.
GraphQL seeks to enforce the concept of getting only what you need, when you need it. This concept is not limited to any sort of technology stack or implementation - it is simply (in my eyes) a philosophy of API design. With GraphQL, your frontend can intelligently query the API for only the data it wants.
This saves time in two huge ways:
- Less data over the wire. Your API is no longer attempting to cram unnecessary information into a response.
- Less processing/filtering by the front-end. Your front-end doesn’t really need to know or care about how the API works. It just wants some data.
Good Captioning

As someone who has a hard time hearing, I really, really appreciated the real-time captions provided by the conference. They were incredibly precise, accurate, and they made my conference experience a lot better. I am used to only hearing 50-60% of a speaker’s talk, and I really loved being able to look to the caption monitors and follow along.
Advanced Django Performance
24 Oct 2018
My latest work project has involved writing a custom Django API from scratch. Due to the numerous business logic and front-end requirements, something like Django Restful Framework wasn’t really a great option. I learned a great deal about the finer points of Django performance while delivering an API capable of delivering thousands of results quickly.
I’ve consolidated some of my tips below.
Model Managers are useful - but beware of chaining them with other queries
Be careful using model managers, especially when working with Django Prefetch data. You will incur additional lookup queries for the operations that your manager performs, as well as any other operations your manager performs on the data (exclude, order_by, filter, etc.).
Avoid bringing Python into it whenever possible
Do everything you can with properly written Models, queries, and prefetch objects. Once you start using Python, you will significantly impact the performance of your application.
Django is fast. Databases are fast. Python is slow.
Use select_related and prefetch_related
Learning to use select_related and prefetch_related will save you a ton of time and debugging. It will also improve your query speeds! As I mentioned above, be careful mixing Model managers with these utilities - also, whenever you begin introducing multiple relationships in a query, you will want to use distinct() and order_by(). Having said that…
Watch out for distinct() gotchas
If you are using advanced Django queries that span multiple relationships, you may notice that duplicate rows are returned. No problem, we’ll just call .distinct() on the queryset, right?
If you only call distinct(), and you forget to call order_by() on your queryset, you will still receive duplicate results! This is a known Django “thing” - beware.
"When you specify field names, you must provide an order_by() in the QuerySet, and the fields in order_by() must start with the fields in distinct(), in the same order."
- Django Docs
Profile your Django queries
You can’t fix what you don’t measure. Make sure DEBUG=True in your Django settings.py file, and then drop this snippet into your code to output the queries being run.
from django.db import connection
# Add this block after your queries have been executed
if len(connection.queries) > 0:
count, time = (0, 0)
for query in connection.queries:
count += 1
print "%s: %s" % (count, query)
time += float(query['time'])
print 'Total queries: %s' % count
print 'Total time: %s' % timeAdvanced Python Performance
24 Oct 2018
Here are some performance hints I learned from doing a deep dive into Python for a work project.
Use map when performance matters AND the functions are complex AND you are using named functions. Use list comprehensions for everything else.
map is a built-in function written in C. Using map produces performance benefits over using list comprehensions in certain cases.
Please note that if you consume an anonymous lambda as your map function, rather than a named function, you lose the optimization benefits of map and it will in fact be much slower than an equivalent list comprehension. I will give you an example of this gotcha below.
def map_it(arr):
return map(square_entry, arr)
def square_entry(x):
return x ** 2
def list_comp(arr):
return [square_entry(x) for x in arr]
def list_comp_lambda(arr):
return [x ** 2 for x in arr]
def for_loop(arr):
response = []
a = response.append
for i in arr:
a(i ** 2)
return responseTo test the performance of these functions, we create an array with 10,000 numbers, and go through the array squaring each value. Pretty simple stuff. Check out the wild differences in runtime and performance:
- List Comprehension with anonymous lambda: 5 function calls in 0.001 seconds
- For Loop: 10005 function calls in 0.048 seconds
- List Comprehension using named function: 10005 function calls in 0.049 seconds
mapwith named function: 10006 function calls in 0.050 seconds
Moral of the story? If you are doing simple list operations, use list comprehensions with anonymous lambdas. They are faster, more readable, and more pythonic.
When you’re munging complex data in Python, it’s a good idea to handle the data modification in a named function and then use map to call that function. You must always profile your code before and after using map to ensure that you are actually gaining performance and not losing it!
You might be asking so, when should I use map?
A good candidate for map is any long or complex function that will perform conditional operations on the provided arguments. map functions are great for iterating through objects and assigning properties based on data attributes, for example.
Here’s an example of map being significantly faster than list comprehensions (shamelessly taken from Stack Overflow):
$ python -mtimeit -s'xs=range(10)' 'map(hex, xs)'
100000 loops, best of 3: 4.86 usec per loop
$ python -mtimeit -s'xs=range(10)' '[hex(x) for x in xs]'
100000 loops, best of 3: 5.58 usec per loopAbuse try/except when necessary - but be careful
If you’re using inline try/except statements (where it’s no big deal if the try block fails), just attempt to do the thing you want to do, rather than using extraneous if statements.
Here’s some sample code and real profiling results to guide your decisions.
import os
import profile
import pstats
# This is a typical example of extraneous if statements
def get_from_array_slow(array, index):
try:
# A typical `if` statement here might check to make sure
# That our array is long enough for the index to be valid
# A perfectly reasonable statement, right?
if len(array) > index:
# Unfortunately, we incur an unnecessary performance penalty due to calling len()
return array[index]
else:
return None
except:
return None
# This is functionally the same at runtime,
# but without the additional len() operation
def get_from_array_fast(array, index):
try:
return array[index]
except:
return None
NUM_TRIALS = 10000
def with_if():
for i in xrange(0, NUM_TRIALS):
get_from_array_slow([], 99) # Out of index
def without_if():
for i in xrange(0, NUM_TRIALS):
get_from_array_fast([], 99) # Out of index
# This is a simple way of using the profile module available within Python
def profileIt(func_name):
tmp_file = 'profiler'
output_file = 'profiler'
run_str = '%s()' % func_name
tf = '%s_%s_tmp.tmp' % (tmp_file, func_name)
of = '%s_%s_output.log' % (output_file, func_name)
profile.run(run_str, tf)
p = pstats.Stats(tf)
p.sort_stats('tottime').print_stats(30) # Print stats to console
with open(of, 'w') as stream: # Save to file
stats = pstats.Stats(tf, stream=stream)
stats.sort_stats('tottime').print_stats()
os.remove(tf) # Remove the tmp file
profileIt('with_if')
profileIt('without_if')Our profiler results are below - using an if took 0.098 seconds - using only try/except shaved off one-third of the compute time, down to 0.065 seconds
profiler_with_if_tmp.tmp
20004 function calls in 0.098 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
10000 0.049 0.000 0.073 0.000 profile_django.py:27(get_from_array_slow)
1 0.025 0.025 0.098 0.098 profile_django.py:51(with_if)
10000 0.024 0.000 0.024 0.000 :0(len)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.098 0.098 profile:0(with_if())
1 0.000 0.000 0.098 0.098 <string>:1(<module>)
0 0.000 0.000 profile:0(profiler)
--------
profiler_without_if_tmp.tmp
10004 function calls in 0.065 seconds
ncalls tottime percall cumtime percall filename:lineno(function)
10000 0.032 0.000 0.032 0.000 profile_django.py:41(get_from_array_fast)
1 0.032 0.032 0.064 0.064 profile_django.py:56(without_if)
1 0.000 0.000 0.000 0.000 :0(setprofile)
1 0.000 0.000 0.065 0.065 profile:0(without_if())
1 0.000 0.000 0.064 0.064 <string>:1(<module>)
0 0.000 0.000 profile:0(profiler)Notice that our function using if incurs twice as many function calls as our plain old try/except block.